
DeepSpeed源码笔记3优化器
父类ZeROOptimizer,用于训练大模型,针对zero stage 3;
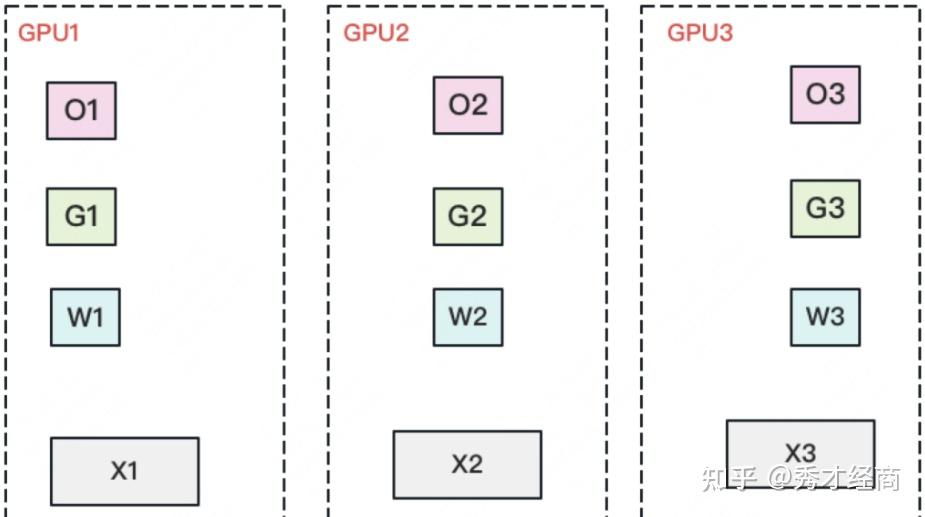
zero stage3:将参数W划分多份,即每个GPU维护各自的优化器状态、梯度和参数;
每块GPU存放一部分参数,将一个batch的数据划分3份,每块GPU读取各自的一份;
做forward时,对W做一次all-gather,取回分布在其他GPU上的W,得到一份完整的W。做完forward后,立刻把不是自己维护的W抛弃;
做backward时,对W做一次all-gather,取回完整的W。做完backward后,立刻把不是自己维护的W抛弃;
做完backward后,计算得到一份完整的梯度G,对G做一次reduce-scatter,从别的GPU上聚合自己维护的那部分梯度。聚合操作结束后,立刻把不是自己维护的G抛弃;
用自己维护的O和G更新W。由于只维护部分W,因此无需再对W做任何allreduce操作;
optimizer:传入的optimizer参数;
flatten:梯度展开操作(即torch中的_flatten_dense_tensors);
unflatten:梯度不展开操作(即torch中的_unflatten_dense_tensors);
dtype:取传入的optimizer参数中模型参数的数据类型;
gradient_accumulation_dtype:float32类型;
_global_grad_norm:0;
custom_loss_scaler:false;
parameter_offload:初始化DeepSpeedZeRoOffload对象,详见initialize_ds_offload函数;
如果zero配置的offload_optimizer或offload_param参数中device属性未设置为"none",则开启offload功能,详见_configure_offloading;
module:传入的模型;
partition_count:进程分组中进程个数;
micro_step_id:0
contiguous_gradients:true;
trainable_param_groups:将优化器optimizer的param_groups中所有训练的参数分组的权重(即params属性)合并成list,统一存入"params"为key的dict中,详见_get_trainable_parameter_groups函数;
将参数分组划分多个参数子分组,详见_create_fp16_partitions_with_defragmentation
从trainable_param_groups中取出每个参数分组中"params"存储的训练参数列表:
按照sub_group_size指定的子分组元素个数将参数分组划分为多个参数子分组,详见_create_fp16_sub_groups函数;
fp16_groups:存放参数分组中每个参数子分组;
fp16_partitioned_groups:参数分组中每个参数子分组的每个参数的ds_tensor构建的list;
sub_group_to_group_id:每个参数子分组在fp16_groups中的索引以及对应的参数分组索引;
fp16_partitioned_groups_flat_numel:每个参数子分组的元素个数;
fp16_partitioned_groups_flat:将fp16_groups中取出各个参数子分组中的16位权重拷贝到新建的一块连续的内存缓冲区后,将原来的权重清空,将各个参数的权重地址指向这块新建的连续内存缓冲区记录到fp16_partitioned_groups_flat中,详见defragment函数;
is_gradient_accumulation_boundary:true;
将ipg_buffer置为None,详见_release_ipg_buffers函数;
previous_reduced_grads:None;
将优化器需要优化的模型参数划分到各个进程上,详见_setup_for_real_optimizer函数;
grad_position:存放fp16_groups中各个参数分组ID以及对应的参数分组索引、向量元素个数起始偏移以及向量元素个数,详见set_grad_positions函数;
创建反向梯度hook用于梯度划分,详见create_reduce_and_remove_grad_hooks函数;
loss_scaler:初始化LossScaler实例;
将bit16_groups中的所有半精度(16位)参数和single_partition_of_fp32_groups中单精度(32位)参数链接起来(将bit16_groups中模型参数的_hp_mapping更新为根据single_partition_of_fp32_groups中该参数对应的张量初始的tensor_fragment,详见link_hp_params函数),用于分布式训练中同步和管理模型的参数,确保所有节点在训练过程中保持一致性,详见_link_all_hp_params函数;
将fp16_partitioned_groups_flat中各个参数分组的16位权重拷贝到fp32_partitioned_groups_flat,并将优化器的param_groups中各个参数分组中的权重(即params属性)清空,详见_create_fp32_partitions函数;
通过barrier操作控制所有进程执行如下动作:
统计fp16_partitioned_groups中各个参数子分组中所有参数向量的元素个数之和,并创建相应大小的零向量作为缓冲区,将每个参数子分组的grad属性指向该缓冲区,如果不是AdaGrad类型optimizer,则根据每个参数子分组的索引从fp32_partitioned_groups_flat中取出对应的权重并以所在的参数分组ID为key存入优化器的param_groups中,随后调用优化器的step初始化状态,最后清空优化器的param_groups中该参数分组的权重,详见initialize_optimizer_states函数;
__ipg_bucket_flat_buffer:初始化大小为reduce_bucket_size的tensor向量;
grad_partitions_flat_buffer:统计fp16_groups中所有模型参数的tensor向量的元素个数,并创建相应大小的零向量;
__param_id_to_grad_partition:存储fp16_groups中每个参数以及在grad_partitions_flat_buffer中该参数对应的切片向量;
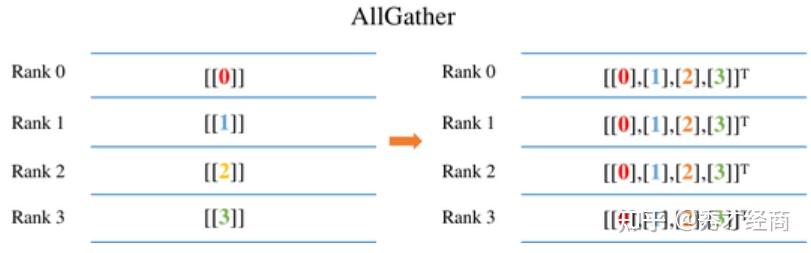
遍历fp16_groups中各个参数分组,调用各个参数分组的all_gather(最终调用_allgather_params)
统计每个参数分组中所有参数的ds_tensor中元素个数之和(即partition_size),并创建进程个数*partition_size大小的向量flat_tensor,每个进程将各自负责该参数分组的部分权重拷贝到该向量flat_tensor中;
通过all_gather_info_tensor分布式操作收集该参数的完整权重到向量flat_tensor中;
将flat_tensor存放的完整模型参数权重拷贝到data字段中;
从模型参数param的grad_fn中获取梯度函数的下一个函数后为梯度函数注册reduce_partition_and_remove_grads钩子函数(当梯度计算完成时自动调用该函数),并将该函数添加到grad_accs中,详见wrapper函数;
根据进程组内进程总数以及该模型参数的权重元素个数计算各个进程各自需要更新的部分权重,每个进程从模型参数param的data字段拷贝出部分权重到ds_tensor字段,然后将data字段存放的完整权重释放,详见_partition_param;
调用loss_scalar的backward进行反向梯度传播计算梯度(即计算各个参数的grad);
由于为每个参数注册了梯度钩子函数,因此计算完各个参数的梯度后,调用reduce_partition_and_remove_grads
初始化parameter_offload的param_coordinators为PartitionedParameterCoordinator,并随后调用reset_step重置每个step相关数据结构;
如果params_in_ipg_bucket中存放向量的元素个数与当前模型参数中的向量元素个数之和大于reduce_bucket_size,则调用__reduce_and_partition_ipg_grads
将params_in_ipg_bucket中的模型参数按照ds_id从小到大排序;
调用all_to_all_quant_reduce或reduce_scatter_coalesced将params_in_ipg_bucket中所有参数的梯度进行累积,存入grad_partitions,详见__avg_scatter_grads函数;
将各个参数在各个micro step的梯度累积结果相加后更新到__param_id_to_grad_partition中,各个参数的梯度(即grad)置为None,详见partition_grads函数;
清空params_in_ipg_bucket;
将当前参数的梯度(即grad字段)拷贝到__ipg_bucket_flat_buffer中,并将该参数的grad字段的data指向__ipg_bucket_flat_buffer中拷贝的梯度,同时将当前参数添加到params_in_ipg_bucket中,详见__add_grad_to_ipg_bucket函数;

统计各个参数的梯度的元素个数并均分为各个进程,并将划分给同一个进程的梯度元素放在相邻内存,所有进程处理的梯度元素拼接在一起,得到tensor_partition_flat_buffer;
将tensor_partition_flat_buffer再次按照进程数切分,得到tensor_partition_buffer_for_each_rank;
通过reduce_scatter分布式操作将tensor_partition_flat_buffer中各个进程的部分梯度元素进行梯度累积,并存入tensor_partition_buffer_for_each_rank,详见_torch_reduce_scatter_fn;
返回各个参数的梯度累积后的结果划分给各个进程的列表;
将各个参数在各个micro step中的梯度进行累积,详见__reduce_and_partition_ipg_grads函数;
averaged_gradients:fp16_groups中每个参数分组从__param_id_to_grad_partition获取对应的存放梯度向量;
micro_step_id:加1;
micro_step_id置为0,详见_pre_step函数;
调用parameter_offload的partition_all_parameters函数将模型参数划分给各个进程?
_global_grad_norm:计算归一化梯度,详见scaled_global_norm函数;
计算averaged_gradients中每个参数分组的梯度的L2范数,计算average_gradients中每个参数分组的梯度的平方和并通过all_reduce分布式操作将梯度平方和同步该进程组其他进程,详见get_grad_norm_direct函数;
累加各个分组参数的梯度的平方和,计算所有参的梯度的L2范数,详见get_global_norm函数;
遍历bit16_groups中各个参数分组:
准备优化器状态、梯度和更新权重,详见_prepare_sub_group函数;
将averaged_gradients中各个参数分组的梯度拷贝到fp32_partitioned_groups_flat中(grad字段);
将micro_step_id置为0,将fp16_groups中各个参数分组的梯度(即grad字段)清空,详见zero_grad函数;
将averaged_gradients中各个参数分组的梯度清空;
将fp32_partitioned_groups_flat中各个参数的梯度按照clip_grad和 _global_grad_norm进行裁剪,按照loss_scale进行缩放(除以loss_scale),详见unscale_and_clip_grads函数;
优化器执行step更新模型权重,同时将参数权重从32位转换到16位,详见_optimizer_step函数;
将fp32_partitioned_groups_flat中各个参数的梯度拷贝到优化器的param_groups中;
执行优化器的step更新模型参数权重;
将优化器的param_groups中参数权重清空;
将fp32_partitioned_groups_flat中当前参数的16位权重(data字段)拷贝到fp16_partitioned_groups_flat中,然后将fp16_partitioned_groups中当前参数分组的16位权重通过_unflatten_dense_tensors操作拷贝到fp16_partitioned_groups中,详见_reassign_or_swap_out_partitioned_parameters函数
将fp32_partitioned_groups_flat中当前参数分组中的梯度(即grad字段)置为None,详见_release_sub_group函数;
将模型参数划分到各个进程上,详见_convert_to_zero_parameters函数
从模型中找到没有被划分(即没有"ds_id"属性)和划分的参数,分别存入non_zero_params和zero_params中;
如果模型中有被划分的参数(即zero_params不为空),则调用convert_to_zero_parameters将non_zero_params中没有被划分的参数转换为划分的参数;否则调用Init(详见下面Init具体实现)划分所有模型参数;
更新模型中每个模块的如下属性,详见_init_external_params函数;
_external_params:初始化为{}
ds_external_parameters:拷贝external_parameters属性
all_parameters:named_parameters和external_parameters中的参数;
将模型中每个模块的_parameters属性初始化为ZeROOrderedDict对象,详见_inject_parameters函数;
根据进程组内进程总数以及该模型参数的权重元素个数计算各个进程各自需要更新的部分权重,每个进程从模型参数param的data字段拷贝出部分权重到ds_tensor字段,然后将data字段存放的完整权重释放,将模型参数的param置为NOT_AVAILABLE,详见_partition_param;
父类InsertPostInitMethodToModuleSubClasses;
_ds_config:根据传入的配置文件路径初始化DeepSpeedConfig;
调用父类InsertPostInitMethodToModuleSubClasses完成初始化;
module:传入模型参数;
将模型参数划分到各个进程上,详见_convert_to_zero_parameters
取出模型中的参数,将每个参数的权重拷贝到local_device指定的设备上;
将模型参数的权重划分到进程组中各个进程上,详见_zero_init_param函数;
更新模型参数param中部分属性(如ds_id从0开始,每个模型参数加1,注册all_gather、partition、partition_gradients等函数),详见_convert_to_deepspeed_param函数;
ds_status:PARTITIONED;
ds_status:AVAILABLE;
ds_tensor:None;
ds_id:从0开始,每个模型参数增加1;
all_gather:all_gather函数;
partition:partition函数;
partition_gradients:partition_gradients函数;
……
如果是rank为0的进程,则通过broadcast操作将模型参数param广播给该进程组中其他进程;
根据进程组内进程总数以及该模型参数的权重元素个数计算各个进程各自需要更新的部分权重,每个进程从模型参数param的data字段拷贝出部分权重到ds_tensor字段,然后将data字段存放的完整权重释放,详见_partition_param;
将模型参数的param置为NOT_AVAILABLE;




热门文章排行
- 共享,正从风口到风险
- 世界十大假戏真做的电影排行榜 真枪实弹太
- 走进涂料市场的秘密
- 在人工智能炒热机器人时,也被人把风带进了
- 生物涂料有什么好处?
- 智能音箱,正走在智能手表的老路上
- “去乐视化”之后,新易到的机会在哪儿?
- 日本十大波涛汹涌巨乳美少女第5名,凶悍!
- 揭开芽笼神秘面纱
- 菜刀材质的3铬钢、5铬钢、9铬钢,差别有
最新资讯文章
- CSS Navigation Bar
- 高考成绩口语合格是什么意思
- 高中物理动力学常见知识点及公式总结
- 2017新人教版部编人教版二年级语文语文
- DOTA2比分
- 2023年零食带货人气主播TOP10揭晓
- 商务部:4月以来电商平台外贸专区销售额超
- 推荐5款主流的私家车小件接单app,帮助
- 英文很蹩脚?如何找到优质的外包写手?怎么
- 2025年中国生物医药产业链图谱及投资布
- 如何打拼音时加上声调?
- 抖音电商618数据发布:超6万个品牌成交
- 物流外包是什么意思_1
- 中国电竞酒店行业现状分析与投资前景预测报
- 长治医学院2021年全日制普通本科招生章
- 书卷一梦_2
- 未成年将禁止参加电竞赛事?网游新规下电竞
- [官方资料]NVIDIA Jetson
- 苏丹伊德理斯教育大学 | 马来西亚苏丹伊
- 2023版美国留学行前准备指南 | 入境



